
Bismillah,
Pada artikel kali ini saya akan menulis tentang pengenalan objek menggunakan OpenCV, di awal sementara kita memanfaatkan model yang sudah ada atau hasil dari training menggunakan tensorflow. Memang model tersebut belum tentu cocok diterapkan pada kasus yang kita hadapi atau kasus di sekitar kita.
Cerita sedikit terkait dengan pengenalan objek untuk pemanfaatan kehidupan sehari-hari, ada yang pernah tentang human counting di suatu ruangan atau di suatu pedestrian? Ya itu salah satu penerapannya kelak, ketika di suatu ruangan sudah diketahui jumlahnya yang ada di dalam tentunya nanti secara automatis bisa disesuaikan suhu ruangan sehingga tidak perlu penggunaan remote AC. Contoh yang kedua terkait pedestrian, tentunya kita bisa mengetahui orang-orang yang berlalu lalang pada trotoar atau pinggir-pinggir jalan. Kedua contoh tersebut tentunya membutuhkan kamera atau Closed-circuit television(CCTV) untuk melakukan perekaman, yang selanjutnya dilakukan pemprosesan.
Kenapa menggunakan OpenCV, yang akan datang agar bisa dimanfaatkan platform yang lain misalkan jika ingin diterapkan pada handphone. OpenCV untuk deep learning memang tidak menyediakan untuk melakukan proses training, akan tetapi support beberapa framework deep learning yang terkenal seperti Caffe, TensorFlow, dan Torch/PyTorch. Pointnya adalah OpenCV dapat digunakan untuk me-load model dari framework yang saya sebutkan di atas untuk melakukan testing.
Sebelum implementasi ke sebuah kode, beberapa sumber daya yang diperlukan adalah zoo model hasil training yang dapat didownload di sini. Zoo model merupakan sebuah kumpulan model yang sudah ditraining untuk mendeteksi objek dari beberapa dataset terkenal seperti COCO dataset, Kitti dataset, Open Images dataset, AVA v2.1 dataset dan iNaturalist Species Detection Dataset. Selanjutnya beberapa sumber daya yang perlu Anda persiapkan adalah sebagai berikut
- Silakan download salah satu dari zoo model, sebagai contoh ssd_mobilenet_v1_coco. Model tersebut merupakan model yang ditraining menggunakan arsitektur MobileNet-SSD pada COCO dataset.
- Kemudian ekstrak hasil download tersebut, isi file tersebut berupa checkpoint(*.ckpt.*), frozen graph proto(*.pb), dan file config(*.config)
- Download file konfigurasi yang digunakan untuk melakukan training di sini, sesuai dengan arsitektur yang digunakan.
- Download file python untuk mengenerate file graph proto(*.pbtxt) di sini dan di sini, disesuaikan dengan arsitektur yang digunakan.
Jika semuanya sudah dilakukan, selanjutnya saya sarankan membuat virtualenv agar project Anda tersusun dengan rapih. Pada postingan yang sebelumnya sudah pernah saya tulis tentang virtualenv, jika sudah silakan ketikkan baris perintah di bawah ini pada terminal atau command prompt untuk membuat file graph proto(*.pbtxt). Langkah ini perlu dilakukan ketika kita menggunakan OpenCV, jika menggunakan python tidak perlu dilakukan ketika melakukan testing model.
python tf_text_graph_ssd.py --input /path/to/model.pb --config /path/to/example.config --output /path/to/graph.pbtxtStruktur direktori projek kira-kira seperti di bawah ini agar memudahkan temen-temen untuk menjalankan projeknya sesuai dengan yang saya dokumentasikan
├── cv_object_detection.py
├── images
│ └── objects.jpg
├── models
│ ├── classes.txt
│ ├── frozen_inference_graph.pb
│ ├── graph.pbtxt
│ └── pipeline.config
├── object_detection.py
├── tf_text_graph_common.py
├── tf_text_graph_faster_rcnn.py
└── tf_text_graph_ssd.py
python tf_text_graph_ssd.py --input models/frozen_inference_graph.pb --config models/pipeline.config --output models/graph.pbtxtOutput yang dihasilkan seperti di bawah ini
Scale: [0.200000-0.950000]
Aspect ratios: [1.0, 2.0, 0.5, 3.0, 0.333299994469]
Reduce boxes in the lowest layer: True
Number of classes: 90
Number of layers: 6
box predictor: convolutional
Input image size: 300x300
Untuk path silakan disesuaikan dengan path di laptop/PC temen-temen, jika berhasil harusnya akan ada file yang terbentuk *pbtxt. Karena kita menggunakan OpenCV, jangan lupa install opencv-python menggunakan command pip. Kira-kira perintah seperti di bawah ini
pip install opencv-pythonYang terakhir adalah implementasi kode menggunakan OpenCV di bawah ini
import cv2 as cv
import os
cvNet = cv.dnn.readNetFromTensorflow('models/frozen_inference_graph.pb', 'models/graph.pbtxt')
path_images = "images"
LABELS = open(os.path.join("models", "classes.txt")).read().strip().split("\n")
font_scale = 1
font = cv.FONT_HERSHEY_PLAIN
rectangle_bgr = (255, 255, 255)
for image_name in sorted(os.listdir(path_images)):
img = cv.imread(os.path.join(path_images, image_name))
rows = img.shape[0]
cols = img.shape[1]
# cvNet.setInput(cv.dnn.blobFromImage(img, 0.017, (300, 300), (127.5, 127.5, 127.5), True, False))
cvNet.setInput(cv.dnn.blobFromImage(img, size=(300, 300), swapRB=True, crop=False))
cvOut = cvNet.forward()
for detection in cvOut[0, 0, :, :]:
score = float(detection[2])
class_id = int(detection[1])
if score > 0.3:
print("Score: {:.4f}, Class id: {}".format(score, class_id))
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
text = "{} {:.2f}".format(LABELS[class_id], score)
(text_width, text_height) = cv.getTextSize(text, font, fontScale=font_scale, thickness=1)[0]
text_offset_x = int(left)
text_offset_y = int(top) - 2
box_coord = ((text_offset_x, text_offset_y), (text_offset_x + text_width-2, text_offset_y - text_height - 2))
cv.rectangle(img, (int(left), int(top)), (int(right), int(bottom)), (255, 255, 255), thickness=2)
cv.rectangle(img, box_coord[0], box_coord[1], rectangle_bgr, cv.FILLED)
cv.putText(img, text, (text_offset_x, text_offset_y), font, fontScale=font_scale, color=(0, 0, 0),
thickness=1)
# cv.namedWindow(image_name, cv.WINDOW_NORMAL)
cv.imshow(image_name, img)
cv.waitKey()Jika dijalankan source code di atas hasilnya seperti di bawah ini
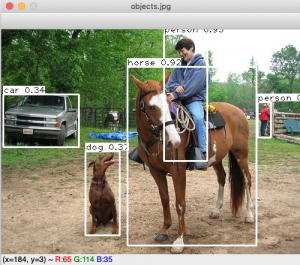
Demikian artikel saya mengenai object detection menggunakan OpenCV dengan model pre-trained, source code lengkap dapat Anda dapatkan di sini. Semoga tulisan saya bermanfaat bagi pecinta computer vision, ditunggu artikel yang selanjutnya ya. cheeers! 🙂